Friday 21st October, 2016
Let’s consider a single week; the figures I’ll use came from a company
I was working with recently. They had a number of developers and
designers working together as an agile team, and although some of the
details I’ll talk about are specific to developers, there are similar
things for designers — or indeed people doing totally different
types of work.
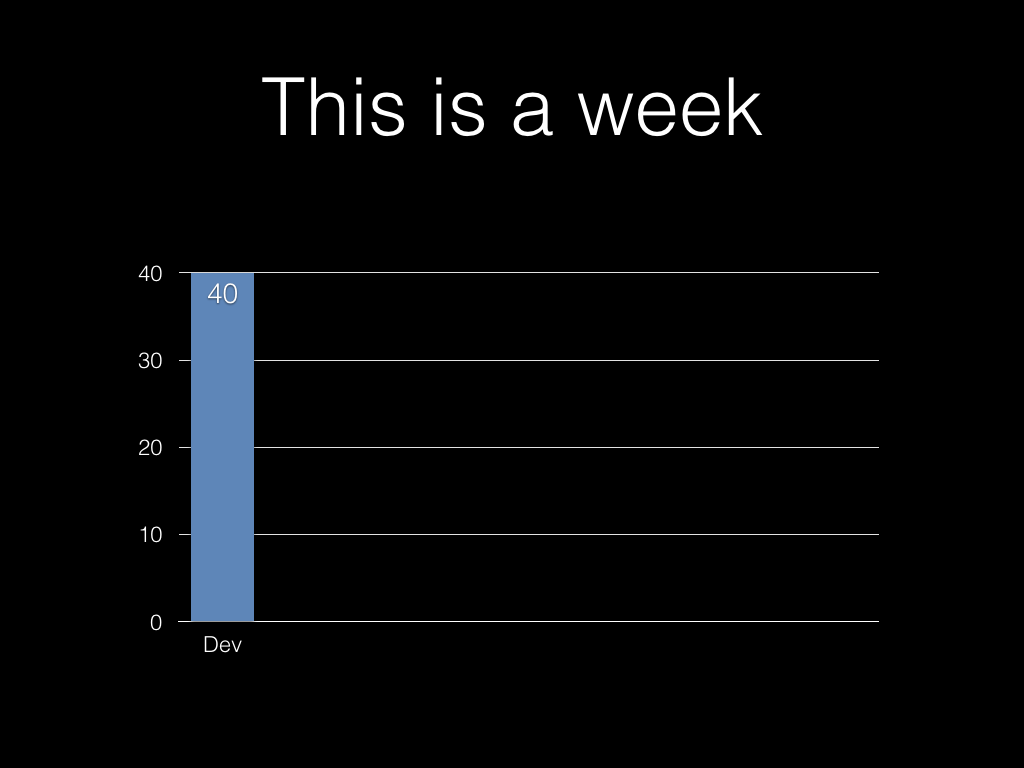
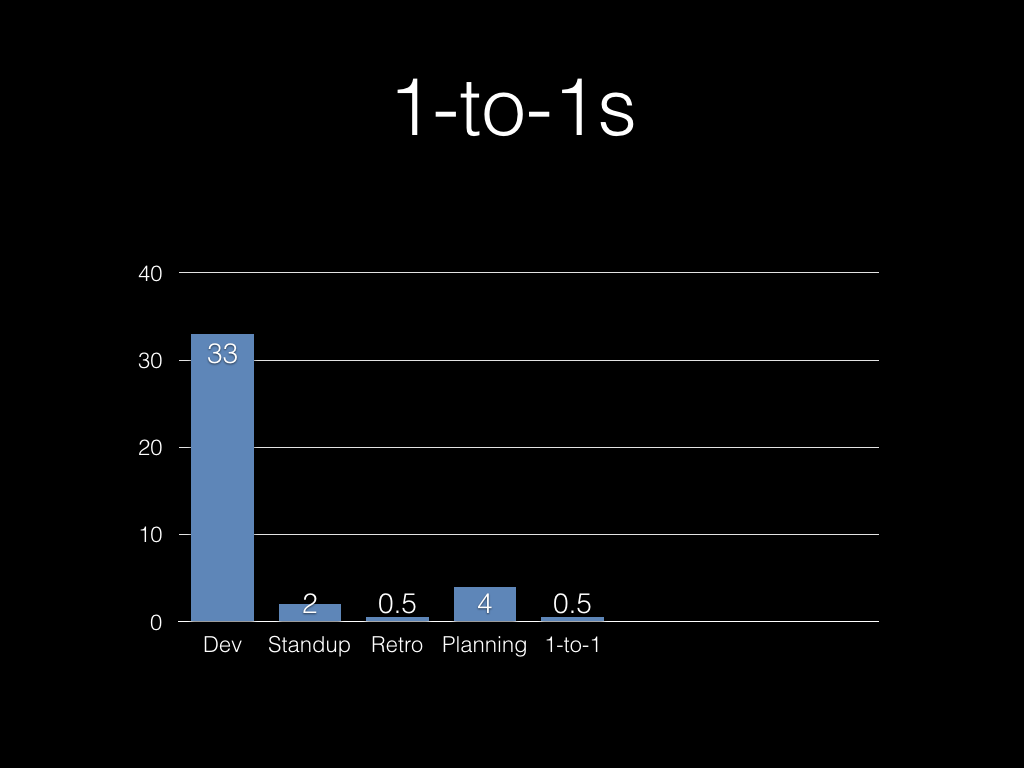
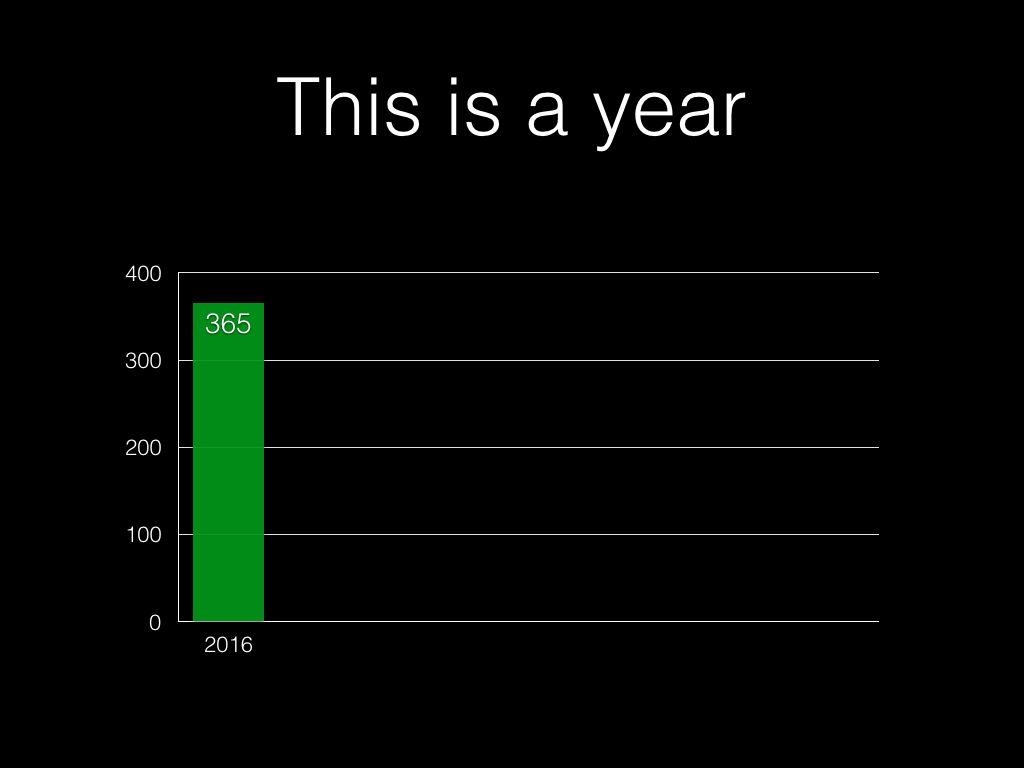
So. What is a week?
Five days Monday to Friday, 9-6 with an hour for lunch. That’s 40
hours.
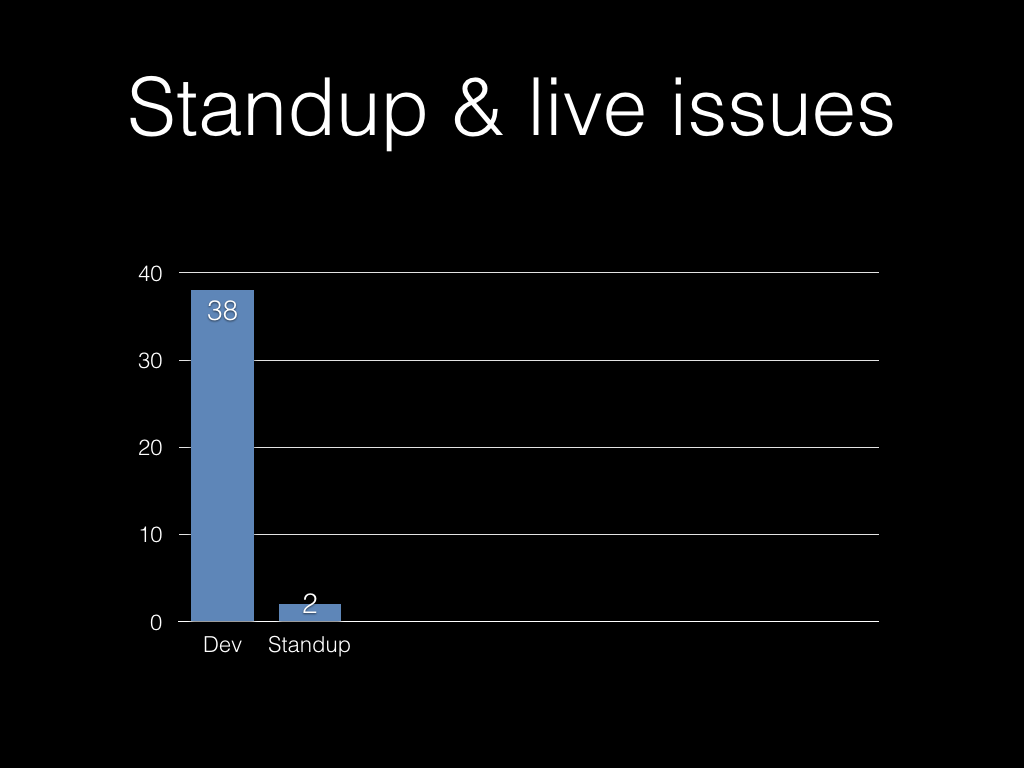
If you’re really efficient, your standup is genuinely five minutes every
day. If you’re honest, a lot of the time it’s 15-20 minutes, particularly
if people start assembling five minutes early, and chat a bit as they
leave. We were more like that.
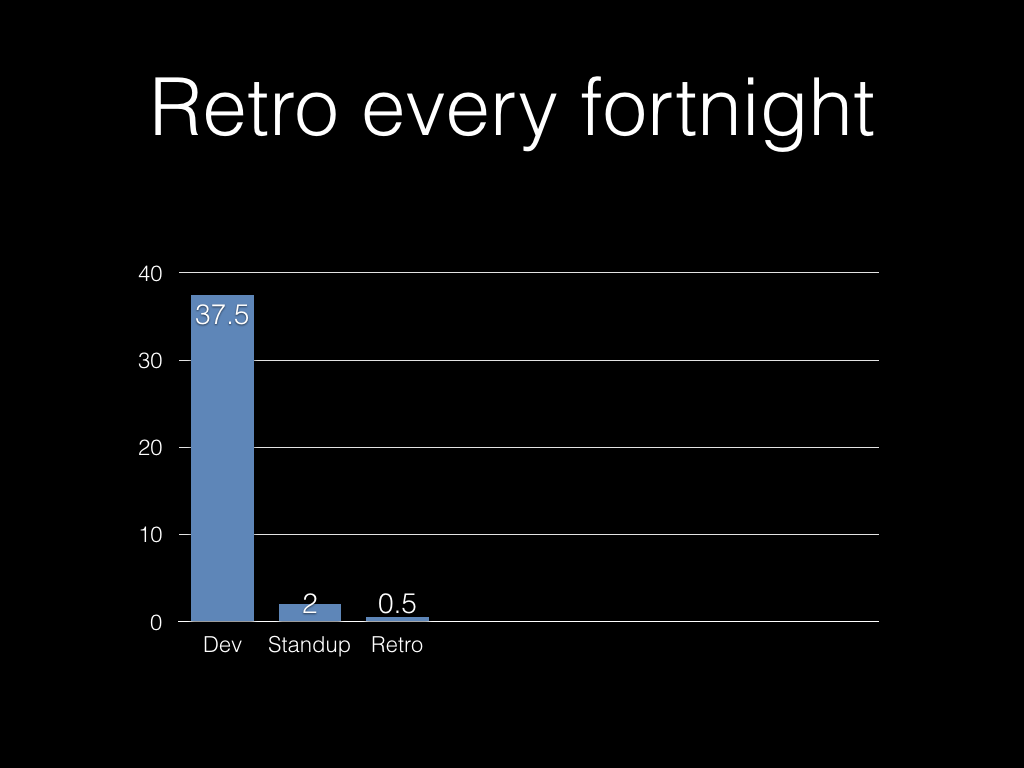
Every iteration we had a retrospective meeting.
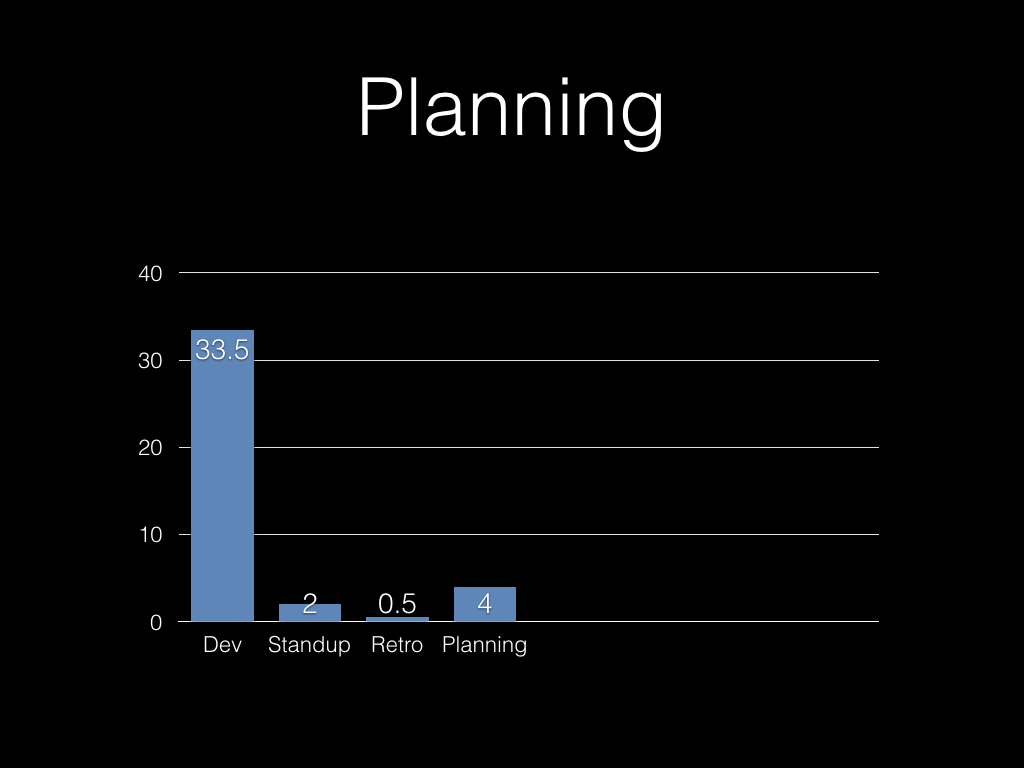
And we spent time as a team every week doing backlog grooming,
estimation and so on. (This wasn’t ideal in some respects, but the whole
team wanted to be involved throughout.)
Hopefully everyone gets a one-to-one meeting with their manager regularly.
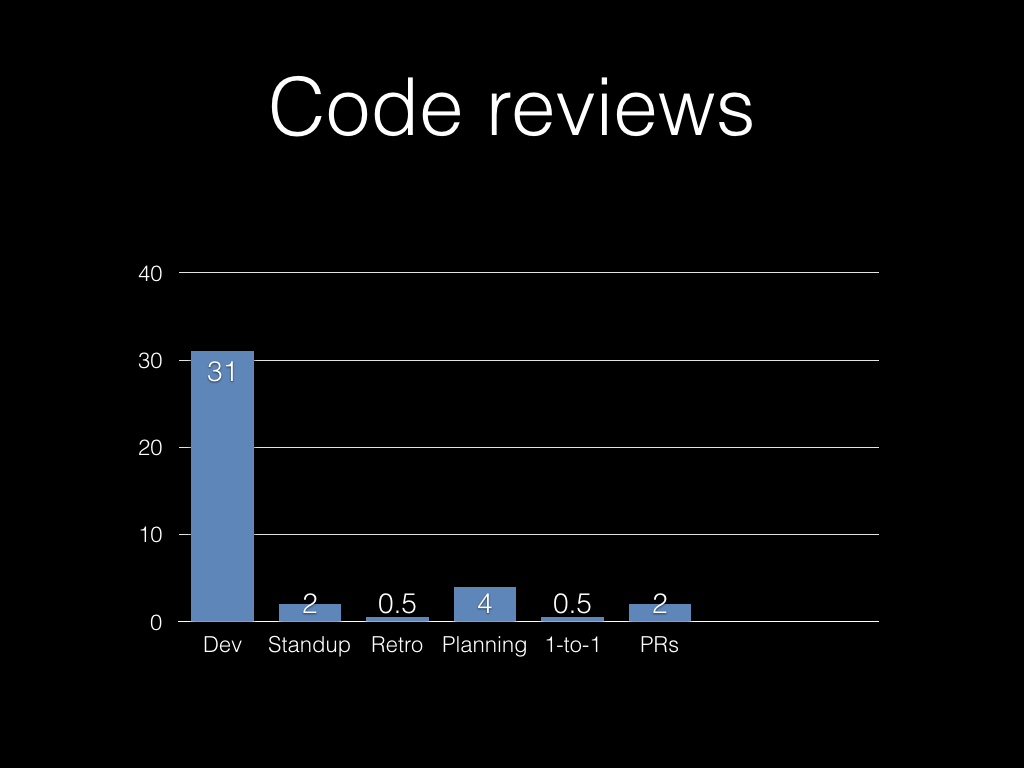
Lots of teams use github Pull Requests or something similar for code reviews.
If each developer spends half an hour a day reviewing others’ work, that’s more than two hours a week.
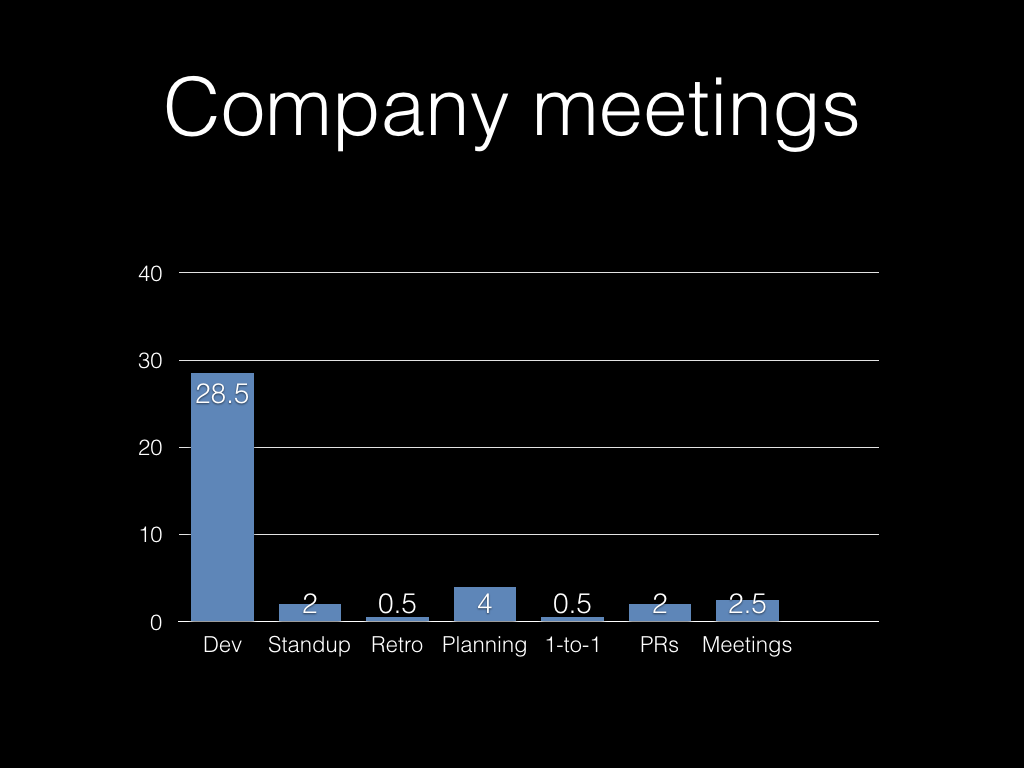
If you’re unlucky, there are lots of company meetings you get sucked into.
If you’re lucky, then you’re probably spending more time on code reviews.
And of course some company meetings are important, so you can’t eliminate
them entirely.
And there’s always other things…
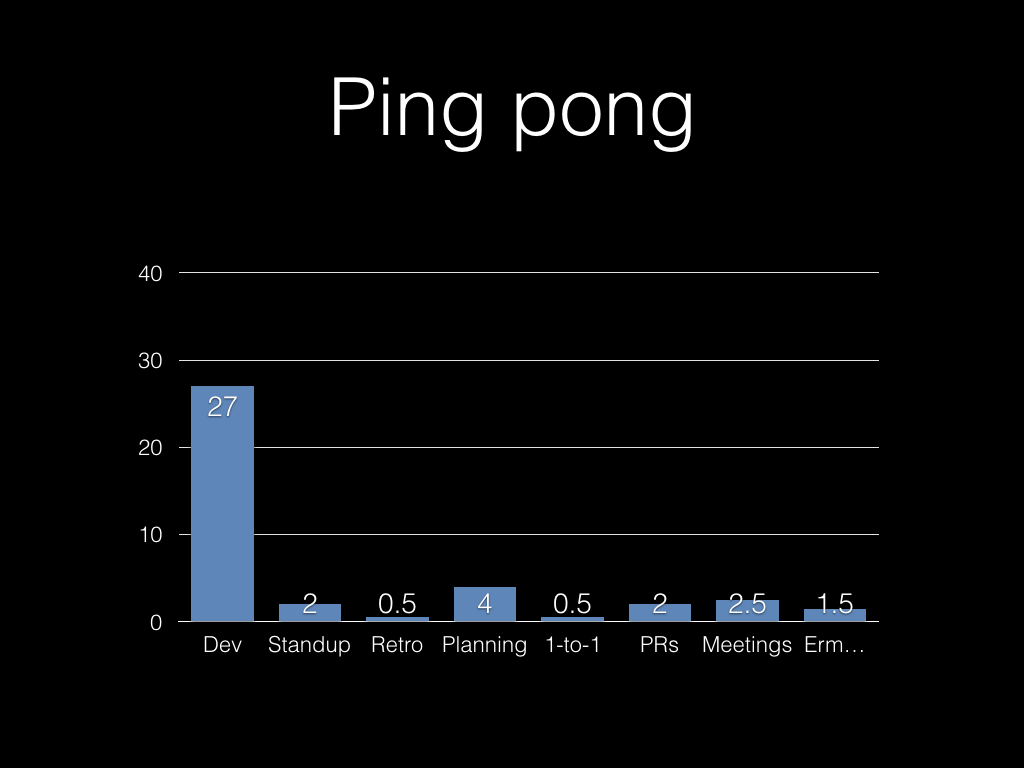
So that leaves us with:

Note that quite a lot of the other thirteen hours are work as
well. But here we’re thinking in terms of the time available to plan,
build, test and deliver new functionality.
27 hours sounds okay, doesn’t it? But we’re not finished yet. Consider a year:
Unless it’s a leap year:
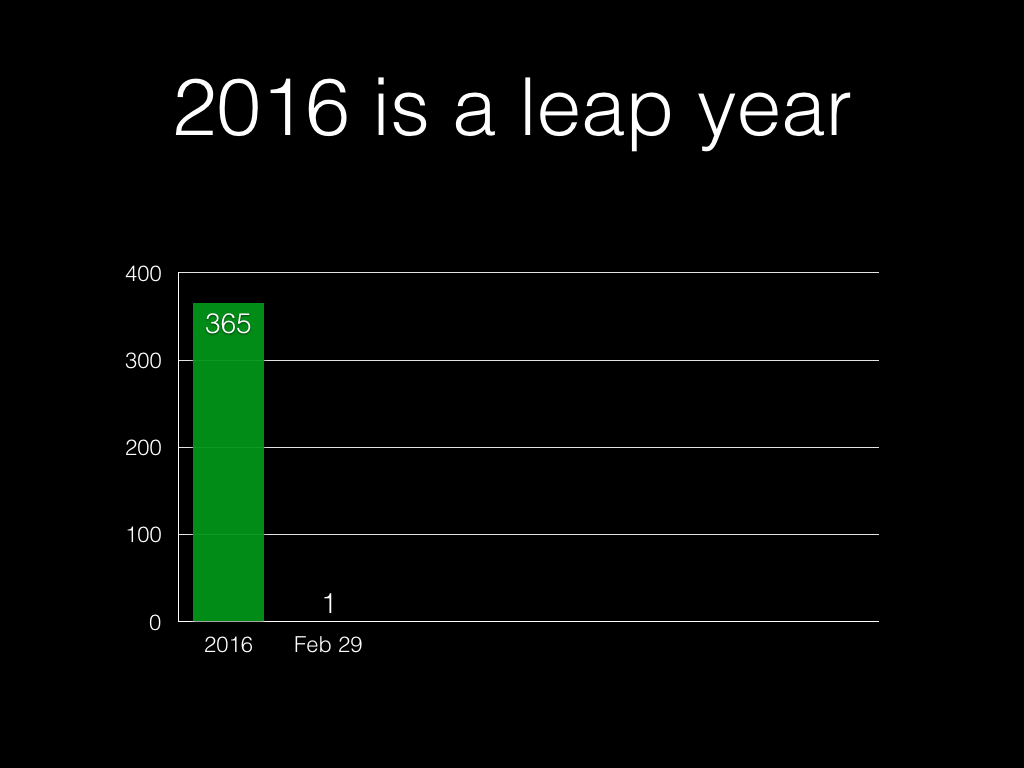
(Let’s pretend it isn’t.)
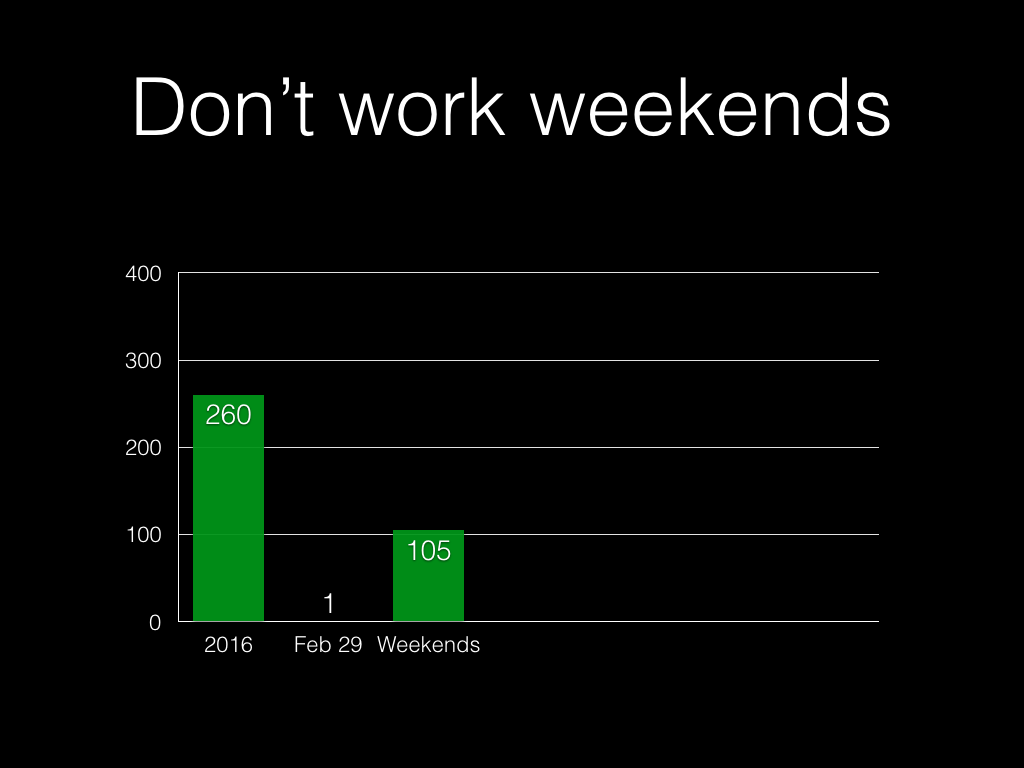
We don’t work weekends. Or at least, we shouldn’t work weekends. Let’s hope
no one is routinely working weekends, because that’s a whole different issue.
In the UK we have eight days that are “statutory holidays”, like 1st May and
“Boxing Day”.
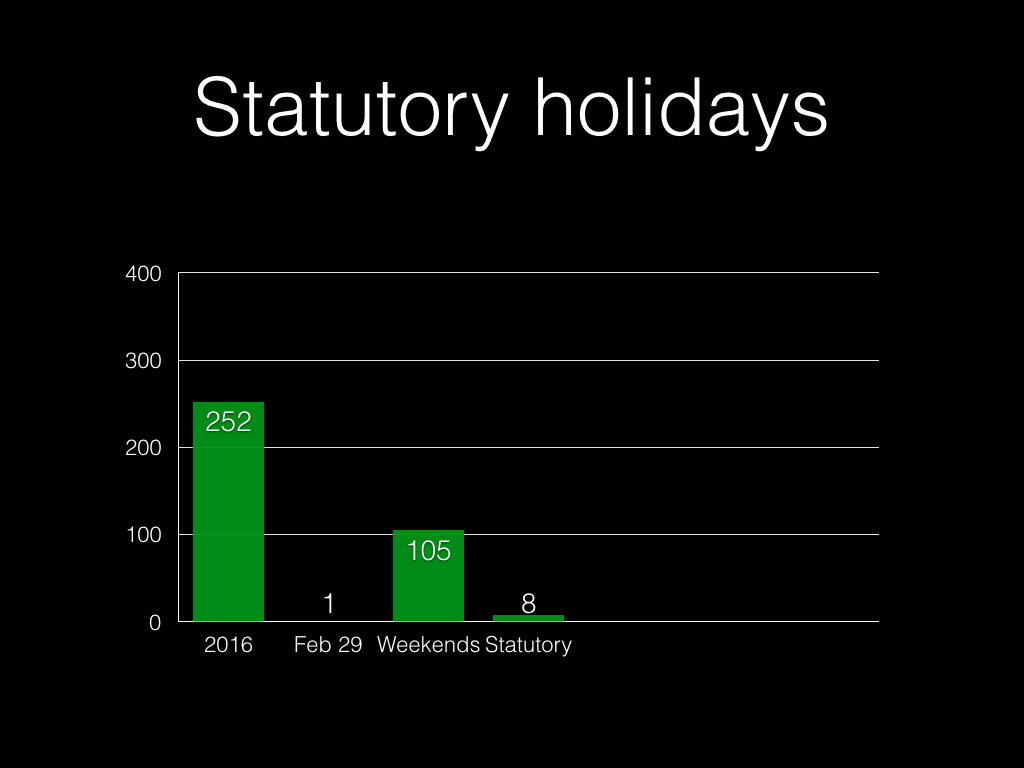
If you’re in fulltime work in the UK, you get another 20 days’ holiday by law.
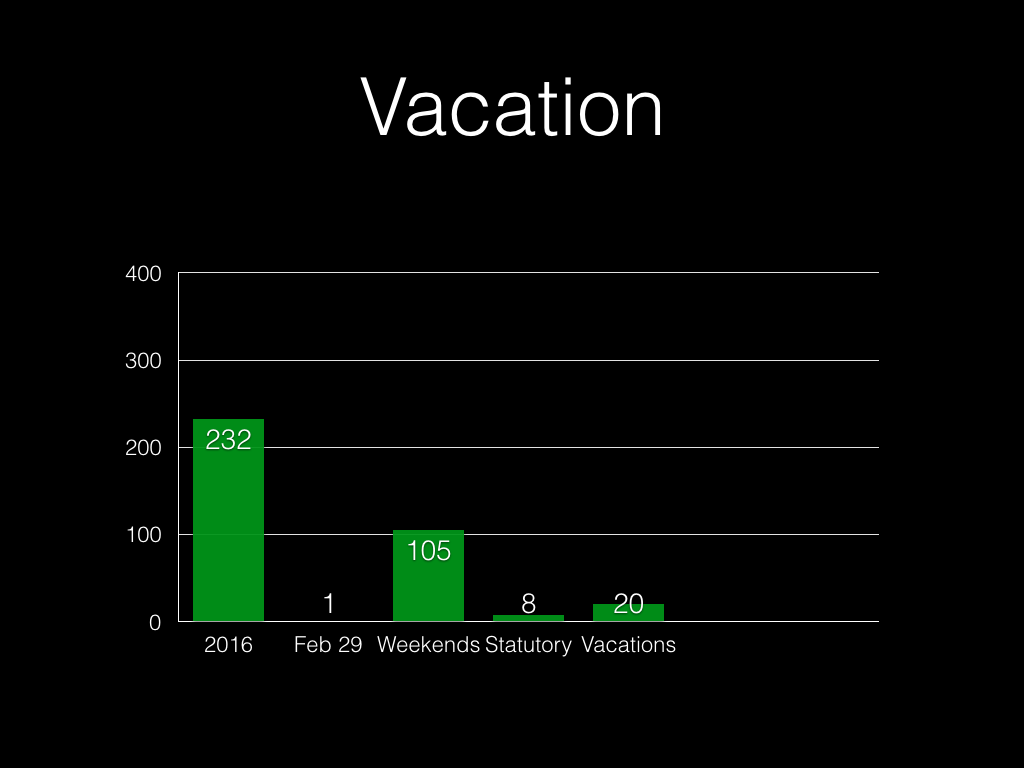
People will take some sick days. (I got this number from averages for the IT
sector in the UK, although it’s quite heavily contested.)
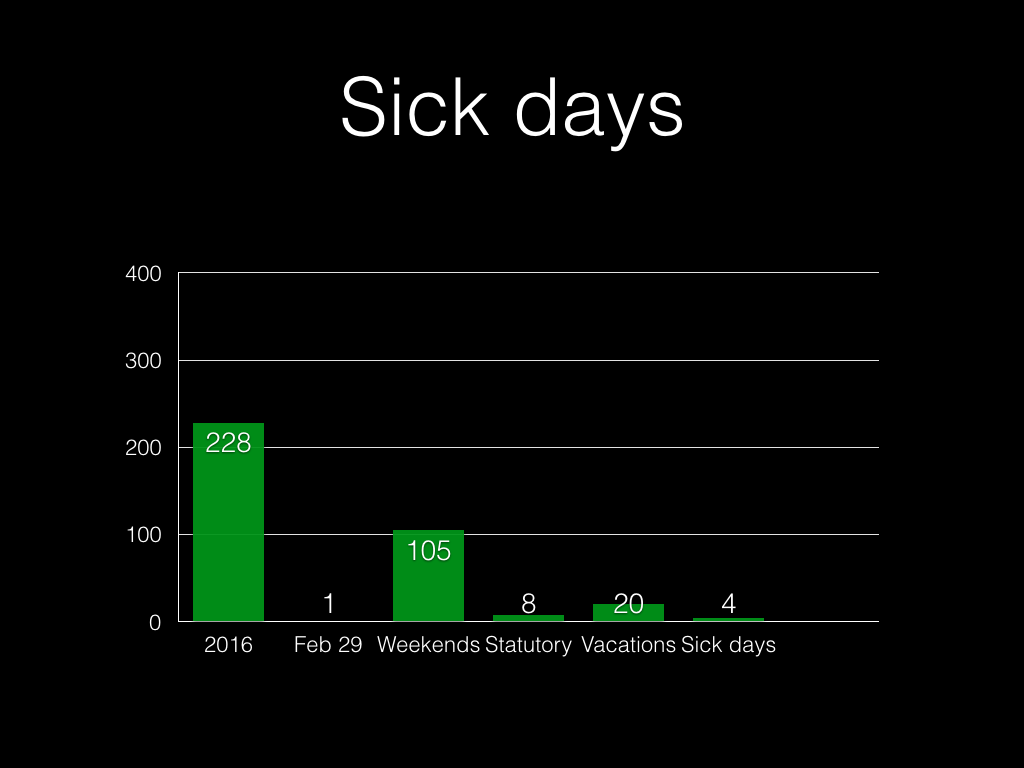
Good companies invest in their employees, whether that’s sending them on
courses, or to conferences, or just giving them the authority to learn new
skills and techniques on company time. Four days is probably the
least-defensible figure here, but it also isn’t completely crazy.
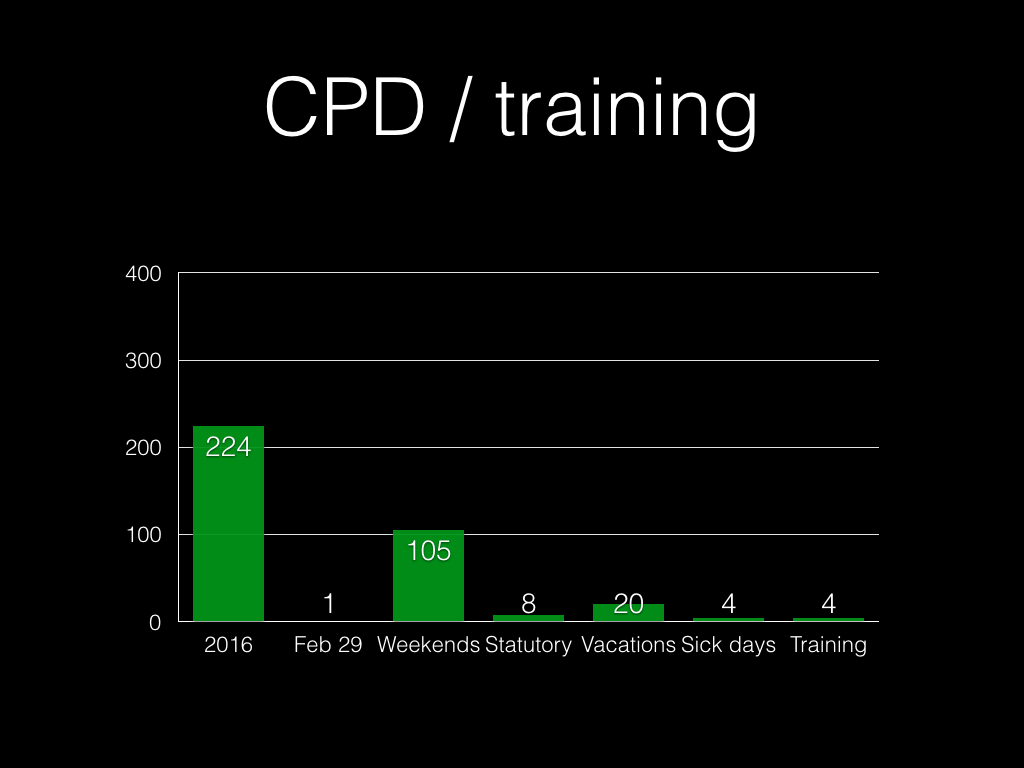
Let’s make it easy on ourselves, and say:

Okay, so with 220 workable days out of 260 weekdays per year, and with 27
“development” hours per week:

So the average week — taking into account holidays, training, sickness and
everything — contains:

Where did it all go? We’ve lost 17 hours per week!
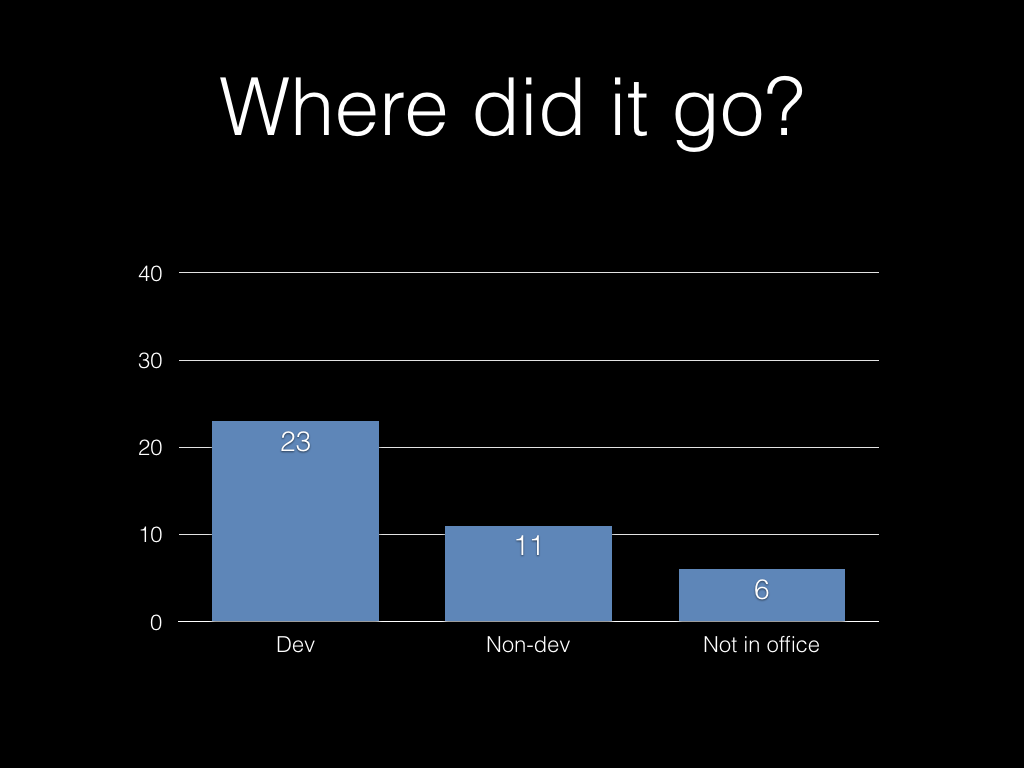
Of course, if you do the sums for your own team you might come out with very different numbers. Maybe you’ll have more development hours, or maybe less. But you aren’t going to get 40 hours per week, every week, out of every team member.
Summary
There are two points here.
Time spent doing productive work is precious, and we should work to defend it against unnecessary meetings and other interruption.
It’s important to recognise that just because someone is a developer doesn’t mean they’re going to spend all their time at a computer typing in code.
Even if you include planning meetings, standups and standing at a whiteboard in “developing”, there are other things that employees need to spend time on: things like CPD, mentoring and one-to-one meetings with their managers are an important part of their job too.
James Aylett, Friday 14th October, 2016
This excellent piece on code
reviews by
Mathias Verraes reminded me of something I generally try to do that
has almost nothing to do with code reviews, which is how I operate on
ticket flow. The bit that triggered me was this:
Another effect is something called ‘swarming’ in Kanban … Stories
are finished faster, and there’s a better flow throughout the
system.
What do we mean by ‘better flow’? For that matter, what do we mean by
‘flow’ in the first place?
What is ticket flow?
You can think of each piece of work that a team does as flowing across
the team’s different functions. The tickets in your development have a
number of states they go through, from “new” (before anyone has done
any substantive work) through to “deployed” (live, or part of a
released version). Here’s a simple example:

Every piece of work that’s valuable has to get to that final state, so
the flow of tickets is the tickets moving through those states from
new to deployed.
Ticket flow therefore is one way of thinking about the work that the
team does. But why does it matter?
Why is flow important?
If you’re familiar with Lean software
development then
you may already have some thoughts here. One of the principles in Lean
is to deliver as fast as possible, which broadly means that we want
tickets to move as quickly as practical through to deployed.
However there’s another Lean principle that’s pertinent here: eliminate
waste, and in particular the waste of waiting, which in software
development terms means tickets sitting around in one state when they
should be moving forwarding toward deployment.
That may sound ideological, but it often makes intuitive sense. For
instance, developers generally would prefer to get changes through
code review as soon as possible after they do the work, so they can
shift their focus completely onto the next piece of work. Worse, with
continuing work by other people introducing changes to the system,
incomplete work can become harder to integrate over time.
If you’re talking about eliminating waste in your process (which is
one of the Lean principles for good reason), then you’re aiming to
reduce the time taken to do things to as close to what’s possible as
you can.
So flow is ‘better’ when…
So a better flow in this sense will be one where waiting time is
minimised. In other words, ticket flow is better when it’s smoother,
ie when tickets move forward without significant hold-up. In practice,
each state has some minimum time to get through to the next; it takes
time to actually build the feature, to go through code review, and so
on. But if you have waiting time, then you have waste you can work to
eliminate.
However it’s not always practical to measure the waiting time of
tickets. For instance, when a piece of work enters code review, what
happens is that it waits until someone has time to look at it. Then
the work of code review begins as that person looks at the code. After
a while they may make some comments, or ask for changes. Then the
ticket will go back into waiting for either the original developer to
address the review, or for another person to review it. All your
review system is likely to record is when individual comments were
added, or when changes were added by the original developer. For some
of the time between the ticket is waiting, and for some of the time
it’s being worked on. If we can’t measure them directly, we should
look for a way to approximate the figures we care about.
A lot of development trackers will provide figures for something
called cycle time, the length of time taken from when the ticket is
picked up (moved from new into “in progress”, or whatever the “being
worked on” state is) and finally marked as complete (deployed, in our
case). However this doesn’t tell us much either, because cycle time
obscures all of the waiting at different points in the ticket’s
flow.
However if we have the cycle time for each ticket, we can visualise
the distribution of cycle time.
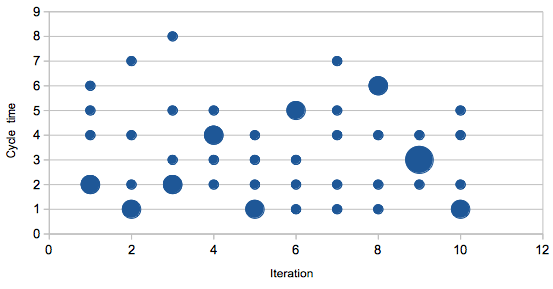
We can also calculate some aspects of that distribution. The average
isn’t going to be terribly interesting, but we can also calculate the
variance, a measure of how spread out the different cycle times
are. A larger variance means less consistency in time taken to
complete the work.
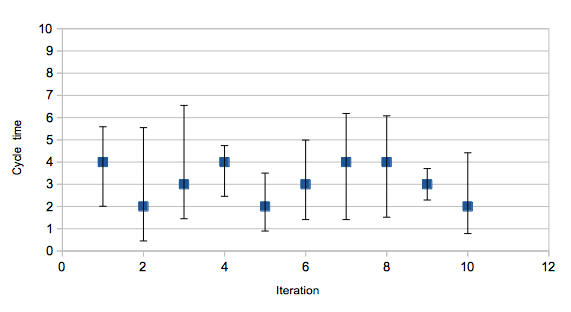
And if we can calculate this for the entire cycle time, we can also do
so for the transitions from one state to another in the ticket flow.
Why is lower variance better?
Say we just look at time taken to get out of the code review
state. The average of recent times gives us an idea of how quickly we
can expect a ticket to pass through this state. However if
that time has high variance, then some tickets will take longer. Some
will take less time.
There are a few reasons this might be the case. Perhaps some types of
work are intrinsically harder to review and so take longer. Or perhaps
one member of the team takes far longer than others to review. Perhaps
one member of the team presents code for review in a way that takes
longer to digest. High variance won’t tell you what the problem is,
but it will highlight that there’s something going on that you should
look into.
I’ve heard people object that since the size of pieces of work isn’t
particularly consistent, the variance will naturally be higher. You
can either divide times by your estimate for the piece of work to try
to normalise this data, or you can work to try to break work up into
more consistently-sized pieces. Although it may sound like that’s
changing your process to fit your measurement abilities, there are
other benefits to having more consistent sizes for work — notably
that they’ll probably be consistently smaller as well, which makes
it more likely for instance that each piece of work can be code
reviewed in one session.
So we can plot average and variance for the different times taken for
tickets to pass through the various states. That will give us a way of
identifying higher variance steps, and also if variance (and average)
are decreasing over time, or at least not increasing.
However there’s another graph we can draw, without any timing data at
all, which gives us a direct way of visualising the ticket flow. Enter
the flow graph, where we graph stacked counts of the different states.
Graphing the flow itself
Consider having five team members. They each pick up a piece of work,
and when they finish their work item it goes into review. They then
immediately pick up another piece of work. Sometime later, once
someone’s had a chance to review their earlier work, and they’ve had a
chance to make any changes, the ticket moves to done. Every so often
someone notices there’s some work waiting to be released, and
everything in done moves to deployed.
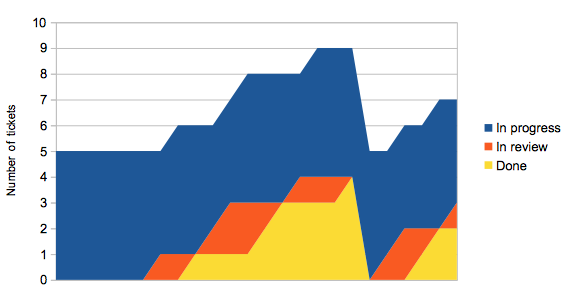
This doesn’t look very smooth, which we should expect because of phrases
like “sometime later” in the description above.
Let’s look at a slightly better scenario, where tickets are reviewed almost
immediately.
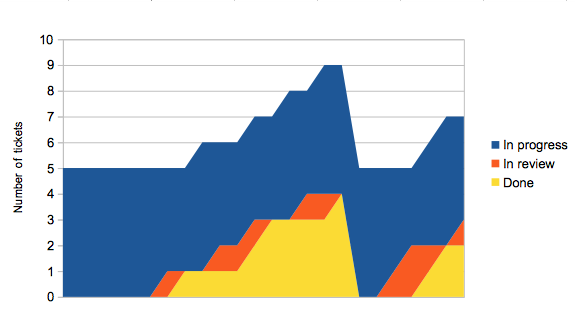
In review tickets pass through to done faster now, but unless we also
deploy more regularly the overall shape of the graph doesn’t change much.
If we change things so that once someone’s work has been reviewed, they’re
responsible for getting it deployed as soon as possible, things start to
look a lot better.
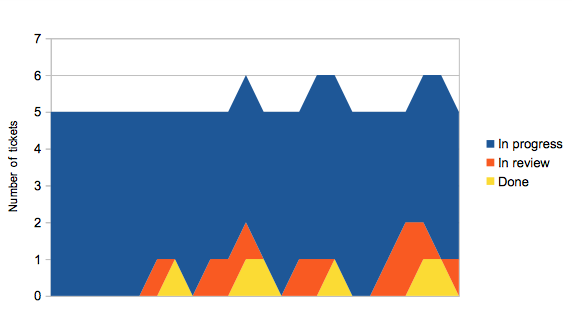
The ‘surface’ of the flow graph tells you how many tickets are ‘in flow’ at any one time — they’ve been picked up but not yet deployed. If your tickets are all a sensible size, and assuming you have a large enough team, this should remain largely constant over time. There’ll be a little variation, for instance if people claim a ticket and start thinking about it while waiting for CI to run ahead of a deploy.
As you’d expect, the overall cycle time is lower in the third
scenario: around 12.5 time units rather than 18 for the first
scenario. The step cycle times are also better, and crucially their
variance is a lot lower. But the most important thing is that in the
third scenario, more features were deployed in that time range than in
the first; there aren’t completed features waiting around to be
deployed.
Note that over the long-term this may not mean you get any more work
done within the team. However that work gets out to users faster; the
waste that’s been eliminated is waiting time of the work, rather
than inefficiency of any team member doing a particular task. (This
means that a team of excellent developers and designers can still have
inefficiencies in their process which you can work to reduce.)
Summary
Ticket flow is a way of thinking of work flowing through your team. We
can use that to investigate potential problems, sticking points in
your process that you should look at. Looking at the distribution
cycle time and time taken within each state of your process gives a
direct numeric representation, or by using a flow graph you can see
the ‘smoothness’ of your process.
The last time I needed this was with a team that used Target Process with a monitoring system based on statsd, and I created a small python script that pulls counts of TP entities out of their API and feeds them to statsd.
James Aylett, Friday 7th October, 2016
Recently, I was talking to someone about how to prioritise and assign
resource for out-of-band work: work that isn’t planned and managed
according to your regular process, but rather appears out of the blue,
whether a problem caught by monitoring or a misfeature reported by a
user.
How do you make sure there’s someone available to do the out-of-band
work? Some out-of-band work needs dealing with immediately, but some
can wait. How do you decide which?
Why is this a problem?
It’s perhaps worth briefly discussing why this can be a significant
problem for agile teams. Surely an agile team can cope with work that
comes in, prioritising it against business needs (perhaps with the
help of a business-side specialist)? Can’t self-organising teams
figure this out?
The trouble is that many performant agile teams rely on the ability to
focus, whether on a single piece of work for the few hours or days it
takes, or a broader feature that chains multiple pieces of work
together to deliver some concrete improvement to end
users. Out-of-band work draws focus.
However a high-performing team can indeed figure this out, coming up
with practices that allow them to respond to out-of-band work without
significantly damaging their focus. They may like to start from these
suggestions, and for teams that are still developing their abilities,
perhaps these ideas can help as well.
Who should do out-of-band work?
There seem to be two options here: either you keep the out-of-band
work within the team, or you put it in a different team.
With the rise of Lean Software Development, and particularly related movements like Devops,
it feels strange to separate out anything that is maintenance work on
your team’s product from the team itself; it runs against a number of
the lean principles. However we’ll consider the implications of doing
just that, as well as a halfway house where some subset of the team is
always split off to work on out-of-band work.
Out-of-band as a separate team
You can have a team alongside the product team whose job it is to
handle out-of-band work. This means that out-of-band issues don’t
impact the product team’s velocity. However there are a number of
significant drawbacks:
splits knowledge of the product between the team responsible for
that product and a separate team — in particular,
Conway’s Law may
start to apply: your software may stop being the shape you need it
to be
if an issue requires knowledge that the out-of-band team doesn’t
have, it will still impact on the product team
career progression for the out-of-band team may be harder to manage
may create conflict counter to the Devops idea of having
operational responsibility within the product team
There’s an exception where most of the out-of-band work is actually
product support (for example helping configure a user’s system, or
setting up a customisation). In that case it may be worth having a
tier of support to handle this. Bugfixes to the product itself I’d
still advocate go to the product team (even if the upstream support
tier can propose those fixes, much as people outside an open source
project can contribute proposed changes).
Out-of-band rotas
Each day, or week, or iteration, you can split off one or more team
members to handle out-of-band issues.
This can work well, although many people don’t like doing it. In
particular, teams or individuals that are worried about their
velocity, rather than using it to guide them, may react against this
way of working because it’s “not what we’re here for”. (This can be
countered by providing a better idea of what the team actually is
there for, encompassing the customer needs that drive doing
out-of-band work.)
However explicitly and constantly changing the “shape” of the team in
this fashion may well reduce cohesion and capability, particularly in
a team with less experienced members, or where knowledge of some parts
of the system is focussed in specific members. While it’s possible for
someone on out-of-band duty to help and support those doing product
development, this starts to look and feel a lot more like the next
option.
Out-of-band agile practices
At the other end of the spectrum of having a separate out-of-band
team, is for all out-of-band work to be handled by the team
directly. While this may seem counter to some agile methodologies,
which often strongly advise against introducing work mid-sprint, I’ve
always viewed specific methodologies as a particular checkpoint on the
path to ideal (although likely idealised and unattainable) agile
working, where work flows through the team on a just-in-time
basis. Providing each work item is also kept small, the team will have
significant flexibility to pick up out-of-band work promptly.
But how quickly is prompt in this case? Should people drop what
they’re doing as soon as a bug comes in?
How should we prioritise out-of-band work?
Some bugs and issues need addressing as soon as they happen. If the
database behind your main product goes down, someone needs to jump on
that. Other issues aren’t so urgent. For instance, if a report is sent
to your finance team every Monday, and one week they notice that some
of the subtotals aren’t correct, you have most of a week to fix
it. (Providing the core figures are correct, finance folk are pretty
nifty with Excel.)
When a new piece of out-of-band work is identified, whether by an
alert from monitoring or exception tracking, a bug coming in from
support, a regression against a preview version of an important web
browser, or the disclosure of a security vulnerability from a
dependency project or supplier, that work must be prioritised in order
to help determine when it should be worked on.
In an ideal world, this would work the same way that any piece of
planned work is prioritised, which depends on a view from whoever is
responsible for product management decisions, guided by advice from
other team members in helping assess the work. For anything that isn’t
drop-everything urgent, you can manage that after raising it at daily
standup, via a daily live bug triage session, or something similar
that fits with your existing practices.
The aim is to give the product manager any information required to
decide which out-of-band requests become work items that should be
picked up in preference to planned work. Other issues that emerge can
be planned in the usual fashion. (Of course, an issue may appear one
day and not be considered a priority, then rise a day or two later if
more, or more important, users run foul of it. You can still manage
things in the same fashion, providing you keep on reviewing issues
that haven’t been resolved.)
Some things that can influence priorities
The following are probably all relevant:
who does it affect? (stakeholders)
how much does it affect them? (stakeholder pain)
how important are they? (stakeholder power)
how long would it take to do the work? (work cost)
The first three are basically an approach to
stakeholder analysis,
which should be unsurprising given its importance in product
management. Taken together with the last, these can then provide a way
of determining both relative priorities within out-of-band work, and
when compared to planned work.
Note that specialist knowledge in the team may be required to come to
a good idea of stakeholder pain as well as work cost. For instance, a
bug that has been reported against one browser but is not an issue on
another may require a developer or QA engineer to evaluate against the
range of browsers and your current user base to determine the level of
stakeholder pain it is causing. (On the other hand, if the report came
from a very important stakeholder, such as a potential new investor,
it may be clear without digging so deep. There are no hard and fast
rules as soon as people are involved.)
Note that you may need to consider other dimensions; for instance a
security vulnerability that does not have a known practical exploit
may require a consideration of risk. A scaling issue surfaced by
monitoring may not (indeed, should not) be causing you problems
today, and so its importance may be dependent on your growth forecasts
for product usage.
Tracking out-of-band work
One of the general problems with out-of-band work is that while you’re
likely to have reasonable practices for measuring things like the
velocity of product work, you’ll have to put some effort into
measuring the out-of-band stuff. However it’s important to do this,
because you want to ensure two things: that you can act to reduce
variance, and that your out-of-band work costs scale reasonably as
your product usage grows.
A common approach is to track the work done after the fact. You
could log time spent, estimate complexity or risk
in story points,
or just file a ticket for every piece of work. They don’t all give
you the same visibility into the out-of-band work being done, but all
are better than measuring nothing.
If you don’t have reliable and consistent tracking of out-of-band
work, you can approximate it by looking at something like velocity
per team member. The trouble is that although it will
indeed be affected by the out-of-band work, that impact is entangled
with a number of others related to team efficiency:
team size can impact communication efficiency, which will have
knock-on effects on velocity per team member
in a small team, the calendrical variance in vacation taken can
cause the same effects as changing team size (you can roughly
control for the direct impact of size changes by averaging over
team strength in days instead of all team members, but that doesn’t
take into account the communication impacts)
environmental factors (noise and seating arrangements) can affect
both individual performance, and communication within the team
distributed and home working, particularly if rare, can have both
environmental and communication impacts
Summary
There are a range of approaches to tackling out-of-band work, which
can be considered along an axis of integration with the product team.
If you’re aiming for your team to release more frequently, to take
complete ownership of its work, and to operate as a
largely-autonomous, self-organising unit then you will want to aim for
out-of-band work to be accepted and managed by the product team it
relates to.
However it may not be possible to do that from where you are now, so
some combination of the other approaches may be helpful.
Whoever ends up doing the work, it needs prioritisation like anything
else. The authority for this rests in the same place as priorities for
planned work, and indeed a lot of the same tools and approaches can be
used to make priority decisions.
No matter how you choose to approach things, you should track the work
so you can measure things that are important to you. You should also,
of course, aim to review and improve your practices over time, both
through regular internal retrospectives, and periodic independent
assessments.
James Aylett, Monday 13th June, 2016
Continuous delivery is one of a number of techniques in building
software intended to reduce the time between working on a change and
getting it into production. The name is explained by Martin
Fowler as follows:
We call this Continuous Delivery because we are continuously running
a deployment pipeline that tests if this software is in a state to
be delivered.
These days, with the rise of automation of production (for instance,
as part of a DevOps way of working), that pipeline will not
only test software but will also build the artefacts used to later
deploy the software to production.
Most of your processes still work
If you think about what it means for a piece of work — say adding a
‘logout’ feature to a website — to be completed, you’ll likely come
up with something like the following aspects:
feature has interaction, visual &c design completed
code is written, including automated tests for the new feature
user documentation is written (including any release notes
required)
test suite passes
sign off acquired (both for the code — via any code review process
— and for the feature itself, signed off by the product manager or
similar)
Scrum calls this a ‘definition of done’, defined as:
Definition of done: a shared understanding of expectations that
software must live up to in order to be releasable into production.
This isn’t any different under continuous delivery, but because we
have an automated delivery pipeline building our deployment artefacts,
this will need to be included. For instance, if you use
Docker to deploy and run your software, your delivery
pipeline will generate Docker images, and upload them to an image
repository, ready to be used in production.
However there can be some challenges in blending continuous delivery
with an agile process.
Everything downstream of your merge should be automated
Say a software engineer on your team, Ashwini, has picked up some
work, written the code and tests and wants to move forward. If the
work comes back some days later with issues, then it will pull them
away from whatever they’ve moved onto in the meantime. We want to
avoid that.
A common process is for a software engineer to do some work, be
actively involved in code review, and then for the code to be
merged. At this point the delivery pipeline can build deployment
artefacts, run automated tests and finally mark this work as ready to
deploy. Unless the tests fail, there shouldn’t be any way that work
moving through the delivery pipeline can revert to Ashwini.
However as well as code review, there are usually some human sign offs
that are needed. For instance there may be some manual testing that
either cannot be or has not yet been automated. The product manager is
likely to want to sign off on work before it is allowed to be made
live.
Ideally you want those sign offs to come before merge. Since code
review should generally not throw back huge changes (assuming everyone
knows what they’re doing and the team is working well together), you
can often get product owner signoff first, then have any manual
testing processes run in parallel to (and perhaps in collaboratoin
with) code review.
I’ve seen teams get product owner signoff by having engineers do ad
hoc demos at their desk. Often QA engineers will drop in as well to
give immediate feedback from their point of view. For a large piece of
work you may want to do this multiple times as the engineer gradually
works through everything they have to do.
This can fall apart if the manual testing takes too long, which is
another good reason to automate as much testing as possible. If a QA
engineer on the team can spend their time on a particular piece of
work in writing automated acceptance tests rather than doing manual
testing, then it can often be done alongside the software engineer’s
work, probably with them directly collaborating.
App stores
You can’t avoid downstream manual work with app stores, because it’s
beyond your control. Your deployment artefact is an app which you
submit to the store, following which there is often some sort of
approval process. To make matters worse, of course, the length of time
taken to give that approval, or not, is often unpredictable and can be
long compared to your own iteration cycle. The combination of a long
pipeline length and late issues causing reversions means that you’ll
have to build more defense in your process for out-of-band work.
Your increment cycle is now shorter than your iteration cycle
A lot of agile teams set their increment (how often they release) the
same as their iteration (how often they plan). Some have increments
longer than their iteration, with the product manager signing off work
in an iteration but it not going live immediately.
With continuous delivery, you have the ability to release pieces of
work as soon as they’re done. Although you may choose to wrap them up
into larger increments, it’s also common to release one or more
increments per day. That’s very different from a once-per-iteration
release, and the processes you have around for instance notifying
users may need to be rethought.
There are some events that typically happen once per iteration which
may no longer make sense. For instance, Scrum teams often have a
showcase of the work they’ve done in an iteration. This may not make
sense if most of the work has already been live for several days,
although some teams like to celebrate the work they’ve done across the
iteration, and may not want to lose that.
It’s also important not to lose sight of the important events that
should continue to happen at the pace of the iteration. A team
retrospective, where the team gets to work on and improve its own
processes and systems, still needs to happen on a regular basis.
Similarly, most teams do some aspects of future planning on an
iteration cycle, through planning meetings, backlog grooming and so
forth.
Going further
An important part of making agile processes work is to have a
self-sufficient team: not just developers and maybe a product manager,
but also the designers, QA engineers and so on that work with
them. This should also include the operations engineers responsible
for production, which is one aspect of DevOps.
However for operations engineers, a feature is never “done” until it’s
shut down. In a Devops and agile way of thinking, that means that
engineers, designers and so forth should also consider a feature to be
“in play” while it’s live. This can result in some interesting
challenges to more rigid adoptions of agile.
If a feature is never done, then it should have regular care and
feeding scheduled. This work should be tracked, just like any other,
which opens all sorts of questions about how features map to pieces of
work (tickets, stories or whatever) in your work tracker.
Further, just because you’re looking at it regularly doesn’t mean that
it will require the same amount of effort each iteration. In planning,
you will need to decide how much time to spend on each live
feature. Having a longer-term view (based around the features) can
help here, so you know in advance when a particular iteration is going
to have larger amounts of effort devoted to “maintenance” work.
James Aylett, Wednesday 16th March, 2016
If you’re using an agile
approach to
manage your project, you’ll have adopted a number of
principles which guide the
way you work. One of these is that the process itself (along with
tools and other working practices) can be changed by the team:
At regular intervals, the team reflects on how to become more
effective, then tunes and adjusts its behavior accordingly.
Typically this is done during team retrospectives, driven either by
impediments the team has encountered, or opportunities to improve,
which are often identified by ideas from outside the team.
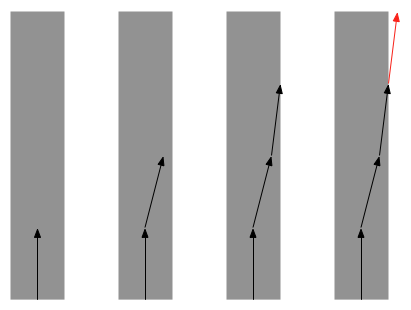
Successive process changes can take a team away from the workable
zone of
practices. Worse,
because of a concept called normalisation of
deviance,
the team may not even be aware when this has happened: unless
something is called out consistently, over time a team may become so
accustomed to something that they no longer consider it to be a
deviance.
However, because in general it’s impossible to predict the best way
for a team to work — and because that may in any case change over
the lifetime of a project — it is important to be able to explore
changes to process with confidence. There are a couple of techniques
you can use here.
Retrospective lookbacks
In your team retrospective, look back at the retrospective notes
from a few retrospectives ago; two or three is a good distance. You
can then review both the changes you made then, and the reasons for
them. This gives the team a clear opportunity to ‘self correct’ a
detail of their process which is no longer appropriate (and perhaps
never was).
Note that some people recommend that the only documentation you
keep of retrospectives is the outcomes: the changes you want to
make going forward. If you do this, you’re throwing away the
‘documentation’ behind that change, which makes fully evaluating
your process in future much harder. If we don’t accept zero
documentation for our code choices, we shouldn’t accept zero
documentation for our process choices.
Get an outside view
As much as review of how and why you got to your current process
may help teams to identify problems, it doesn’t directly attack the
issue of normalisation of deviance. For this, it’s a good idea to
get someone from outside the team to review where you are. Their
fresh perspective can help highlight problems, and help to identify
deviance.
It’s increasingly common for companies to arrange ‘field trips’,
where teams from different companies spend time learning from each
other, and this can be a good source of the input
needed. Alternatively, consultants with experience of a range of
different companies and their processes can provide not only an
outside view but also ideas and possible solutions from across the
industry.
It’s important to remember that having a process detail that isn’t
working is not a failure of anybody. Even if it never served the
team well, it may have been an entirely reasonable thing to
try. What’s important is identifying and changing them rather than
letting them continue to damage the team.
James Aylett, Wednesday 9th March, 2016
If you’re thinking of process changes in terms of an agile
possibility space, then you
already have the concept of fitness, or how well your current set of
processes serve the team and the project.
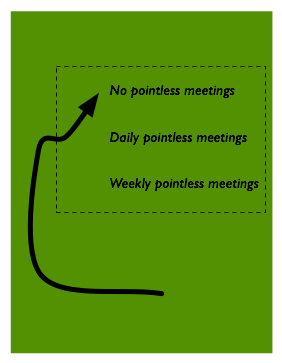
Some choices will have only a minor impact on fitness, but others can
have significant upsides or cause major problems. As the team explores
the possibility space, therefore, the fitness of its current position
will change. Even a succession of small changes in fitness can have a
significant impact over time, so more important than the change in
fitness caused by one change is how your fitness is doing over time.
At any point in time, there is a subset of all the possible process
options that will actually work well together, a workable zone
within the possibility space. Moving outside the zone will cause the
team significant issues. (Exactly where you put the boundaries of the
zone depends on how much you’ll accept lowered process fitness while
you explore the possibility space.)
Moving about within the zone may increase or decrease productivity,
happiness or other measures of team success, but aren’t significantly
harmful, so it’s a comfortable place to explore. Providing you’re
paying attention to the success of your process changes, it’s often
possible for a team to recognise when it strays outside the workable
zone, and to make a suitable correction.
However there may be multiple workable zones, perhaps with very
different working practices, so sometimes a bold set of changes will
produce a better outcome than making smaller changes within the
current workable zone.
This idea may frighten people, but it shouldn’t. In agile software
development we’ve adopted various practices that enable us to make
bold changes to code. Tests give us confidence before we commit to a
change, and monitoring tells us if things went wrong after the
fact. I’ll probably write more at some stage about both of these, but
there are analogues in adapting your process that can help overcome
a fear of moving quickly.
James Aylett, Wednesday 2nd March, 2016
There are many different options that a team may take when adopting or
adapting its processes. For instance:
- an explicit daily standup, or an asynchronous approach with daily
updates circulated by team members
- how long the team’s cycle is, governing the frequency of forward
planning meetings, team retrospectives and so forth
- cake Wednesdays?
The total range of options can be thought of as a possibility space,
which allows us to think of the current practices as being at a
particular point in that space, with the team able to move in a number
of different directions by making different choices.

Choices will either make things better or worse for the team (or have
no overall impact). We could think theoretically in terms of each
position in the space, itself a combination of different choices,
having a ‘fitness’ number. So for instance a team distributed across
several timezones would likely have a higher value of fitness for
daily updates than for a daily standup at a particular time, because
they may not all be able to attend.
There may be more than one ‘current best position’. In fact, with the
number of process choices a team is likely to have available to them,
there probably will be more than one — and there could be many. If
we think of a possibility space in two dimensions only, we could
imagine a map of some landscape, with fitness being the height. Maybe
you can visualise a team, scrambling over rocks or running down
gullies, trying to find the best place to be right now.

One benefit of thinking like this is that it focusses our attention
away from trying to find the “one true best methodology” and onto
exploring the space. Teams sometimes have to try things out to see
if they work, and it’s often not possible to know what the best set of
choices are in advance. Certainly there is no universal ‘best
position’: it’s dependent on both the current team and the current
situation. If you’re on a mountain and someone twists their ankle, or
there’s an unexpected thunderstorm, your idea of the best place to be
will change. Similarly, changes to team composition, project demands,
and other environmental factors from outside the team, will affect good
process choices.
If you think of adapting a team’s process as an adventure in
possibility space, it can also make it more clear how important it is
that the entire team is involved. An idea of which direction to strike
out in — which process change to try — can come from anyone, but
should be implemented with everyone’s
consent.
Of course, the possibility space for most teams will have many more
than two dimensions. Additionally, because the ‘success’ of a process
choice can be measured in different terms (such as happiness of team,
short-term velocity, long-term defect rate and so forth), you can’t
really assign just one number; in fact, you often can’t fully predict
the outcome of a particular process choice. However conceptually (and
mathematically) this doesn’t matter so much, and it’s useful to have a
metaphor for things.
James Aylett, Tuesday 1st March, 2016
When I was at Artfinder, one of the
rituals we developed by accident was cake Wednesdays. What started
as ensuring we had cake for important milestones, such as our first
anniversary (when we launched, for reasons I can no longer remember
we celebrated with liquorice pipes and Brunel
expressions),
eventually became a competitive challenge of attempting to out-do
previous weeks. Someone baked or brought a cake, and the company
shared status and updates across teams. And we ate the cake.
I’ve talked about this occasionally since then as accidental (as in
unintended) but welcome culture, something that just emerged from the
personalities around Artfinder at the time. I’d never urge anyone to
do exactly the same, because these things have to grow organically
from the team. However I was delighted to discover recently that
someone else independently invented cake
Wednesdays!
I hope they’re still doing them.
More recently, while I was consulting for
Scoota and completely independently of me,
one of their summer social activities was a
GBBO-style
competition. Sadly not on Wednesdays, so they don’t get to join the
club.